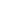Hey readers! Welcome to the next episode of training on neural networks. We have been studying multiple modern neural networks and today we’ll talk about autoencoders. Along with data compression and feature extraction, autoencoders are extensively used in different fields. Today, we’ll understand the multiple features of these neural networks to understand their importance.In this tutorial, we’ll start learning with the introduction of autoencoders. After that, we’ll go through the basic concept to understand the features of autoencoders. We’ll also see the step by step by step process of autoencoders and in the end, we’ll see the model types of autoencoders. Let’s rush towards the first topic:
What are Autoencoders?
Autoencoders are the type of neural networks that are used to lear ...
Hello pupils! Welcome to the next section of neural network training. We have been studying modern neural networks in detail, and today we are moving towards the next neural network, which is the Echo State Network (ESN). It is a type of recurrent neural network and is famous because of its simplicity and effectiveness.
In this tutorial, we’ll start learning with the basic introduction of echo state networks. After that, we’ll see the basic concepts that will help us to understand the work of these networks. Just after this, we’ll see the steps involved in setting the ESNs. In the end, we’ll see te fields where ESNs are extensively used. Let’s start with the first topic:
Introduction to Echo State Networks (ESNs)
The echo state networks ( ...
Hello learners! Welcome to the next episode of Neural Networks. Today, we are learning about a neural network architecture named Vision Transformer, or ViT. It is specially designed for image classification. Neural networks have been the trending topic in deep learning in the last decade and it seems that the studies and application of these networks are going to continue because they are now used even in daily life. The role of neural network architecture in this regard is important.
In this session, we will start our study with the introduction of the Vision Transformer. We’ll see how it works and for this, we’ll see the step-by-step introduction of each point about the vision transformer. After that, we’ll move towards the difference between ViT and CNN and in the end, we’ll discuss th ...
Hello pupils! Welcome to the next session of the neural network series. I hope you are doing good. In the previous part of this series, I showed the double deep Q networks and discussed their differences from the deep Q network to make things clear. Today, I am going to visit a very popular neural network with you. This is the spiking neural network that mimics the functionality of the biological neurons with the help of spikes. This is a different neural network than the traditional networks and you will see the details of each point.
In this lecture, we’ll understand the introduction of the spiking neural network. We’ll discuss all the basic terms that are used while studying the SNN. After that, we’ll move on to the steps of using SNN in detail. In the end, we’ll move towards the appl ...
Hey pupils! Welcome to the next session on modern neural networks. We are studying the basic neural networks that are revolutionizing different domains of life. In the previous session, we read the Deep Q Networks (DQN) Reinforcement Learning (add link). There, the basic concepts and applications were discussed in detail. Today, we will move towards another neural network, which is an improvement in the deep Q network and is named the double deep Q network.
In this article, we will point towards the basic workings of DQN as well so I recommend you read the deep Q networks if you don’t have a grip on this topic. We will introduce the DDQN in detail and will know the basic needs for improvement in the deep Q network. After that, we’ll discuss the history of these networks and learn ab ...
Hello readers! Welcome to the next episode of the Deep Learning Algorithm. We are studying modern neural networks and today we will see the details of a reinforcement learning algorithm named Deep Q networks or, in short, DQN. This is one of the popular modern neural networks that combines deep learning and the principles of Q learning and provides complex control policies.Today, we are studying the basic introduction of deep Q Networks. For this, we have to understand the basic concepts that are reinforcement learning and Q learning. After that, we’ll understand how these two collectively are used in an effective neural network. In the end, we’ll discuss how DQN is extensively used in different fields of daily life. Let’s start with the basic concepts.
...
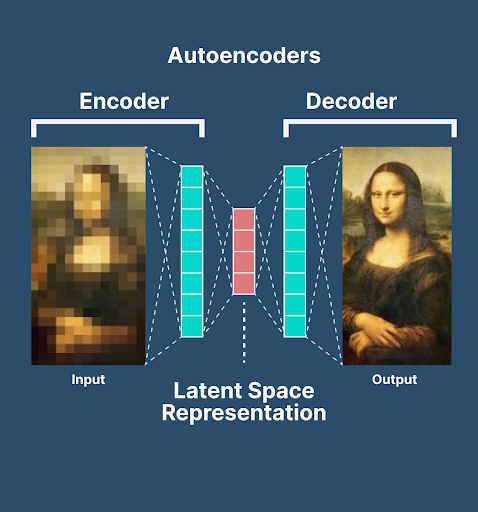
Hello! I hope you are doing great. Today, we will talk about another modern neural network named gated recurrent units. It is a type of recurrent neural network (RNN) architecture but is designed to deal with some limitations of the architecture so it is a better version of these. We know that modern neural networks are designed to deal with the current applications of real life; therefore, understanding these networks has a great scope. There is a relationship between gated recurrent units and Long Short-Term Memory (LSTM) networks, which has also been discussed before in this series. Hence, I highly recommend you read these two articles so you may have a quick understanding of the concepts.
In this article, we will discuss the basic introduction of gated recurrent units. It is better ...
Hey readers! Welcome to the next lecture on neural networks. We are learning about modern neural networks, and today we will see the details of residual networks. Deep learning has provided us with remarkable achievements in recent years, and residual learning is one such output. This neural network has revolutionized the design and training process of the deep neural network for image recognition. This is the reason why we will discuss the introduction and all the content regarding the changes these network has made in the field of computer vision.In this article, we will discuss the basic introduction of residual networks. We will see the concept of residual function and understand the need for this network with the help of its background. After that, we will see the types of skip connec ...
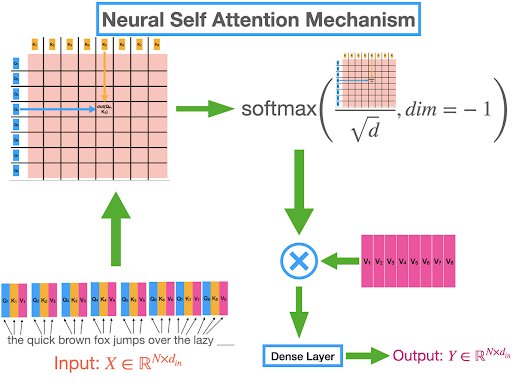
Deep learning is an important subfield of artificial intelligence and we have been working on the modern neural network in our previous tutorials. Today, we are learning the transformer architecture neural network in deep learning. These neural networks have been gaining popularity because they have been used in multiple fields of artificial intelligence and related applications.
In this article, we will discuss the basic introduction of TNNs and will learn about the encoder and decoders in the structure of TNNs. After that, we will see some important features and applications of this neural network. So let’s get started.
What are Transformer Neural Networks
Transformer neural networks (TNNs) were first introduced in 2017. Vaswani et al. h ...
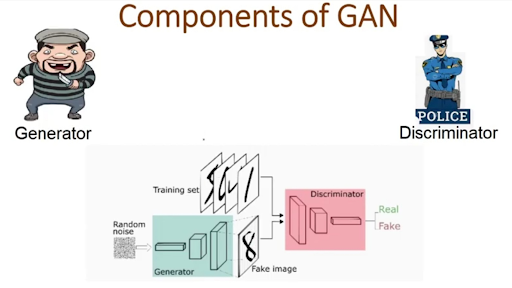
Deep learning has applications in multiple industries, and this has made it an important and attractive topic for researchers. The interest of researchers has resulted in multiple types of neural networks we have been discussing in this series so far. Today, we are talking about generative advertising neural networks (GAN). This algorithm performs the unsupervised learning task and is used in different fields of life such as education, medicine, computer vision, natural language processing (NLP), etc.
In this article, we will discuss the basic introduction of GAN and will see the working mechanism of this neural network, After that, we will see some important applications of GANs and discuss some real-life examples to understand the concept. So let’s move towards the introduction of GANs ...