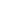In the previous topic, we have discussed data types in C++ in detail. Today we will discuss variables and constants in C++.
A named memory location or memory cell is called a variable. The program's input data and its results are stored in variables during execution. During the execution of the program, the value of a variable can be changed but its name can not be changed.
Variables are created in random access memory. As we know that RAM is a temporary memory so data stored in it is also temporary. It can only be used during execution. When the program ends, the data stored in the variable is automatically removed.
In C++, all the variables are declared first:
Name of variable: an identifier that represents a memory location.
Address of v ...
In the previous section, we have had an overview of a detailed Introduction to C++. Today, we will have a look at the data types in C++. It's our 2nd tutorial in the C++ programming language series.
In the previous tutorial, we have seen the basics of C++ and have also discussed a small code. We have discussed various programming terms in the previous tutorial and from now on, we are going to discuss those terms in detail. So, today's lecture is on Data Types in C++, let's get started:
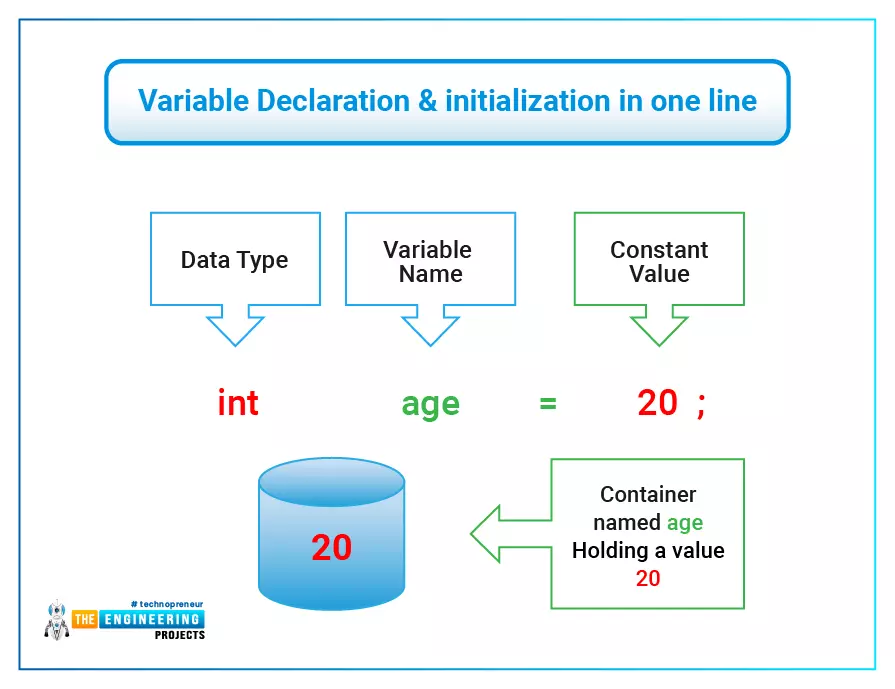
C++ Data Types
A data type defines the type and the set of operations that can be performed on the data. Various types of data are manipulated by the computer. The data is given as an input to the program. According to the program's set of instructions, data is pr ...
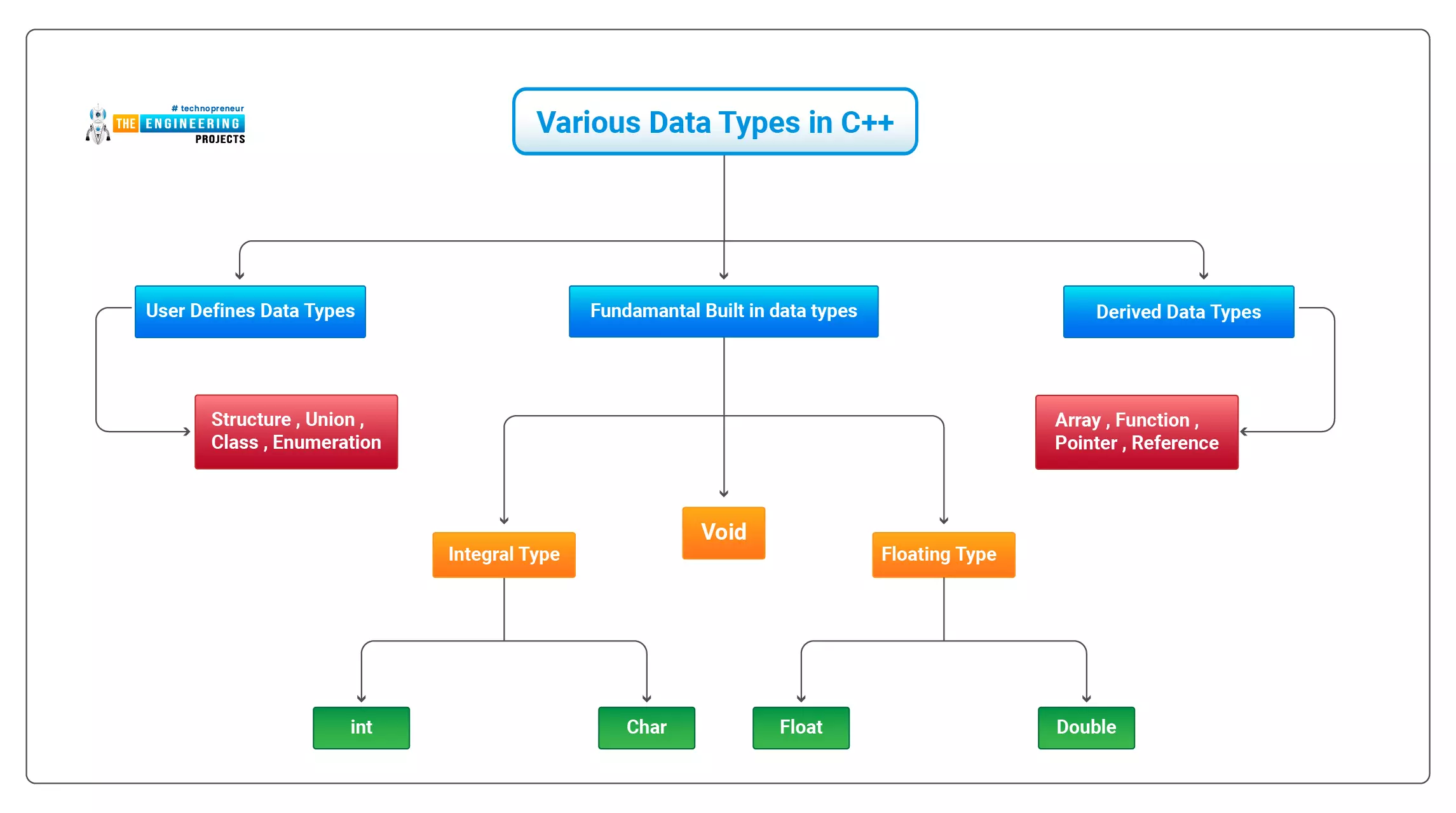
The Internet of Things (IoT) philosophy may be viewed as a highly dynamic and radically dispersed networked system comprised of a huge number of identifiable smart devices. These objects may communicate and interact with one another, as well as with end-users and other network entities. As the Internet of Things era begins, the usage of small, inexpensive, and flexible computer hardware that allows end-user programming becomes more prevalent. The Raspberry Pi, a fully configurable and programmable tiny computer board, is one of them discussed in this article. Although there are certain limitations, the Raspberry Pi remains a low-cost computer that has been used effectively in a wide range of IoT vision research applications despite its few shortcomings.
...
Hello friends, I hope you all are doing great. In today's tutorial, I am going to give you a detailed introduction to the C++ Programming language. In cross-platform programming languages, C++ is the most popular that can be used to work on low and high-level applications. Bjarne Stroustrup was the founder of C++. He modified C language to develop C++ language. Control over system resources and memory can be attained by using C++. In 2011, 2014, and 2017 it was modified to C++11, C++14, and C++17. C++ is a middle-level language. It is advantageous to both programming languages low-level (drivers, kernels) and higher-level applications (games, GUI, desktop apps etc.).
Uses of C++
C++ is one of the world's most famous programming languages. It is u ...
Do you care about SEO? Then you must protect your content from scrapping. You can lose the competitive advantage and revenues to content scraping. Google can penalize you if they detect that your content is plagiarized. You can incur losses in your website traffic up to 99%. Since content is the primary driver of traffic and sales, protecting it from scrapping and others increases your sales and boost your SEO. Content scraping is carried out by bots called scrappers controlled and commanded by a cybercriminal. Scrapper bots repurpose the scrapped content to malicious actions. These actions include copyright violation, duplicating the content to an attacker’s website, and stealing organic traffic. To understand how to protect yourself from scrappin ...