
































Transformer Neutral Network in Deep Learning


























Deep learning is an important subfield of artificial intelligence and we have been working on the modern neural network in our previous tutorials. Today, we are learning the transformer architecture neural network in deep learning. These neural networks have been gaining popularity because they have been used in multiple fields of artificial intelligence and related applications.
In this article, we will discuss the basic introduction of TNNs and will learn about the encoder and decoders in the structure of TNNs. After that, we will see some important features and applications of this neural network. So let’s get started.
What are Transformer Neural Networks
Transformer neural networks (TNNs) were first introduced in 2017. Vaswani et al. have presented this neural network in a paper titled “Attention Is All You Need”. This is one of the latest additions to the modern neural network but since its introduction, it has been one of the most trending topics in the field of neural networks. The basic introduction to this network:
"The Transformer neural networks (TNNs) are modern neural networks that solve the sequence-to-sequence task and can easily handle the long-range dependencies."
It is a state-of-the-art technique in natural language processing. These are based on self-attention mechanisms that deal with the long-range dependencies in sequence data.
Working Mechanism of RNN
As mentioned before, the RNNs are the sequence-to-sequence models. It means these are associated with two main components:
- Encoder
- Decoder
These components play a vital role in all the neural networks that deal with machine translation and natural language processing (NLP). Another example of a neural network that uses encoders and decoders for its workings is recurrent neural networks (RNNs).
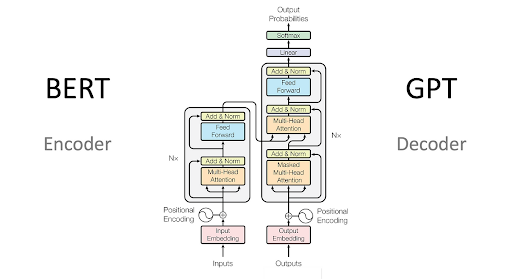
RNN Encoder’s Working
The basic working of the encoder can be divided into three phases given next:
Input Processing
The encoder takes the input in the form of any sequence such as the words and then processes it to make it useable by the neural network. Thai sequence is then transformed into the data with a fixed length according to the requirement of the network. This step includes procedures such as positional encoding and other pre-processing procedures. Now the data is ready for representation learning.
Representation Learning
This is the main task of an encoder. In this, the encoder captures the information and patterns from the data inserted into it. It takes the help of recurrent neural networks RNNs for this. The main purpose of this step is to understand dependencies and interconnected relationships among the information of the data.
Contextual Information
In this step, the encoder creates context or hidden space to summarise the information of the sequence. This will help the decoder to produce the required results.
RNN Decoder’s Working
Source text
The decoder takes the results of the contextual information from the encoder. The data is in the hidden state and in machine translation, this step is important to get the source text.
Output Generation
The decoder uses the information given to it and generates the output sequence. In each step of this sequence, it has produced a token (word or subword) and combined the data with its own hidden state. This process is carried out for the whole sequence and as a result, the decoded output is obtained.
The transformer pays attention to only the relevant part of the sequence by using the attention mechanism in the decoders. As a result, these provide the most relevant and accurate information based on the input.
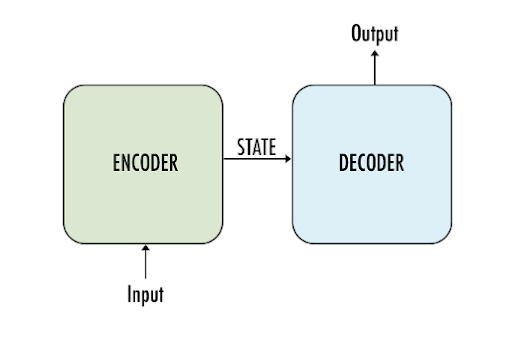
In short, the encoder takes the input data and processes it into a string of data with the same length. It is important because it adds contextual information to the data to make it safe. When this data is passed to decoders, the decider has information on the contextual data, and it can easily decode the information and pay attention to the relevant part only. This type of mechanism is important in neural networks such as RNNs and transformer neural networks; therefore, these are known as sequence-to-sequence networks.
Features of Transformer Neural Network Architecture
The TNNs create the latest mechanism, and their work is a mixture of some important neural networks. Here are some basic features of the transformer neural network:
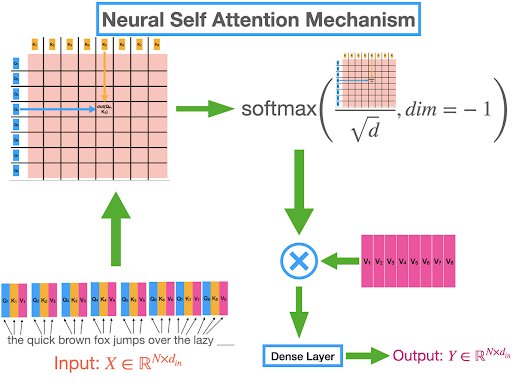
Self Attention Mechanism
The TNNs use the self-attention mechanism, which means each element in the input sequence is important for all other elements of the sequence. This is true for all the elements; therefore, the neural network can learn long-range dependencies. This type of mechanism is important for tasks such as machine translation and text summarization. For instance, when a sentence of different words is added to the TNNs, it focuses more on the main word and applies the calculations to make sure the right output is performed. When the network has to translate the sentence “I am eating”, from English to Chinese, it focuses more on “eating” and then translates the whole sentence to provide the accurate result.
Parallel Processing
The transformer neural networks process the input sequence in a parallel manner. This makes them highly efficient for tasks such as capturing dependencies across distant elements. In this way, the TNNs takes less time even for the processing of large amount of data. The workload is divided into different core processors or cores. The advantage of multiple machines in this network makes them scalable.
Multi-head Attention
The TNNs have a multi-head mechanism that allows them to work on the different sequences of the data simultaneously. These heads are responsible for collecting the data from the pattern in different ways and showing the relationship between these patterns. This helps to collect the data with great versatility and it makes the network more powerful. In the end, the results are compared and accurate output is provided.
Pre-trained Model
The transformer neural networks are pre-trained on a large scale. After this process, these are fine-tuned for particular tasks such as machine translation and text summarization. This happens when the usage of labeled data is on a small scale in the transformer. These networks learn through this small database and get information about patterns and relationships among these datasets. These processes of pre-training and fine-tuning are extremely useful for the various tasks of natural language processing (NLP). Bidirectional Encoder Representations from Transformers (BERT) is a prominent example of a transformer pre-trained model.
Real-life Applications of TNNs
Transformers are used in multiple applications and some of these are briefly described here to explain the concept:
- As mentioned before, machine translation is the basic application of a transformer neural network. Different platforms are using this for the translation of one language into another at different levels. For instance, Google Translate uses the transform to translate the content over more than 100 languages.
- Text summarization is another important application of TNNs. This neural network can read long articles in just a bit and can provide a summary without skipping any important concept.
- The question answering is easy with the transformer neural network. The text is inserted into the QA application and it provides instant replies and answers. The text may be on any topic therefore, such software is used in almost every field of life.
- The TNNs are widely used to create software that can instantly provide the codes for different problems and applications. A good example in this regard is the AlphaCode software which is used for the generation of code with the help of simple prompts. This is generated by DeepMind and the TNNs are used for the basic working of this software.
- The chatbots and websites are being created with the TNNs that can easily provide creative writing on different topics. For instance, the Chat-GPT is a large language model that is created by openAI. It can create, edit, and explain different text types such as poems, scripts, codes, etc.
- The automatic conversation is an important application of TNNs because it has omitted the need for physical operators on different systems. The chatbots and conversational AI systems can now talk to the customers and users and provide them the logical and human-like replies in no time.
Hence, we have discussed the transformer neural network in detail. We started with the basic definition of the TNNs and then moved towards some basic working mechanisms of the transformer. After that, we saw the features of the transformer neural network in detail. In the end, we have seen some important applications that we use in real life and these use TNNs for their workings. I hope you have understood the basics of transfer neural networks, but still, if you have any questions, you can ask in the comment section.